Hola Ricardo,
Si ya tienes la informacion sobre las isoformas ya descritas, efectivamente
solo tendrias que hacer el mapeo y luego el recuento.
Para ello, simplemente descarga del genbank las secuencias de las isoformas
que quieras comparar y las metes en un fichero fasta. En el paper, no veo
referencia de genbank accesion. Con ello igual lo que tienes que hacer es
preparar tu las secuencias.
Con ello volvemos al ensamblaje de isoformas. Si has lanzado cufflinks sobre
un mapeo de tophat este te ensamblara todas las isoformas posibles, no deberia
tardar nada (no es un ensamblaje de contigs) sino
de isoformas a partir de reads mapeados con tophat. Esto lo lanzaste no? Te
salio el transcriptoma consenso?
Alternativamente si las isoformas son simplemente distintos splicings de los
exones existentes, puedes construir tu las secuencias usando seqeditor, aqui
leerias el fichero con el genoma de interes (seqeditor es capaz
de leer cromosomas enteros) y llamas el cromosoma donde este el gen el el
browser. Simplemente cuando leas el fichero del genoma te saldra una lista con
todas las secuencias que tiene dicho genoma (chrom 1, chrom 2 etc)
tienes que cliquear en la secuencia donde el gtf te diga que esta el gen de
interes, e ir a las distintas posiciones de los exones para hacer sus
combinaciones en base a lo que diga el paper. Las secuencias que obtengas
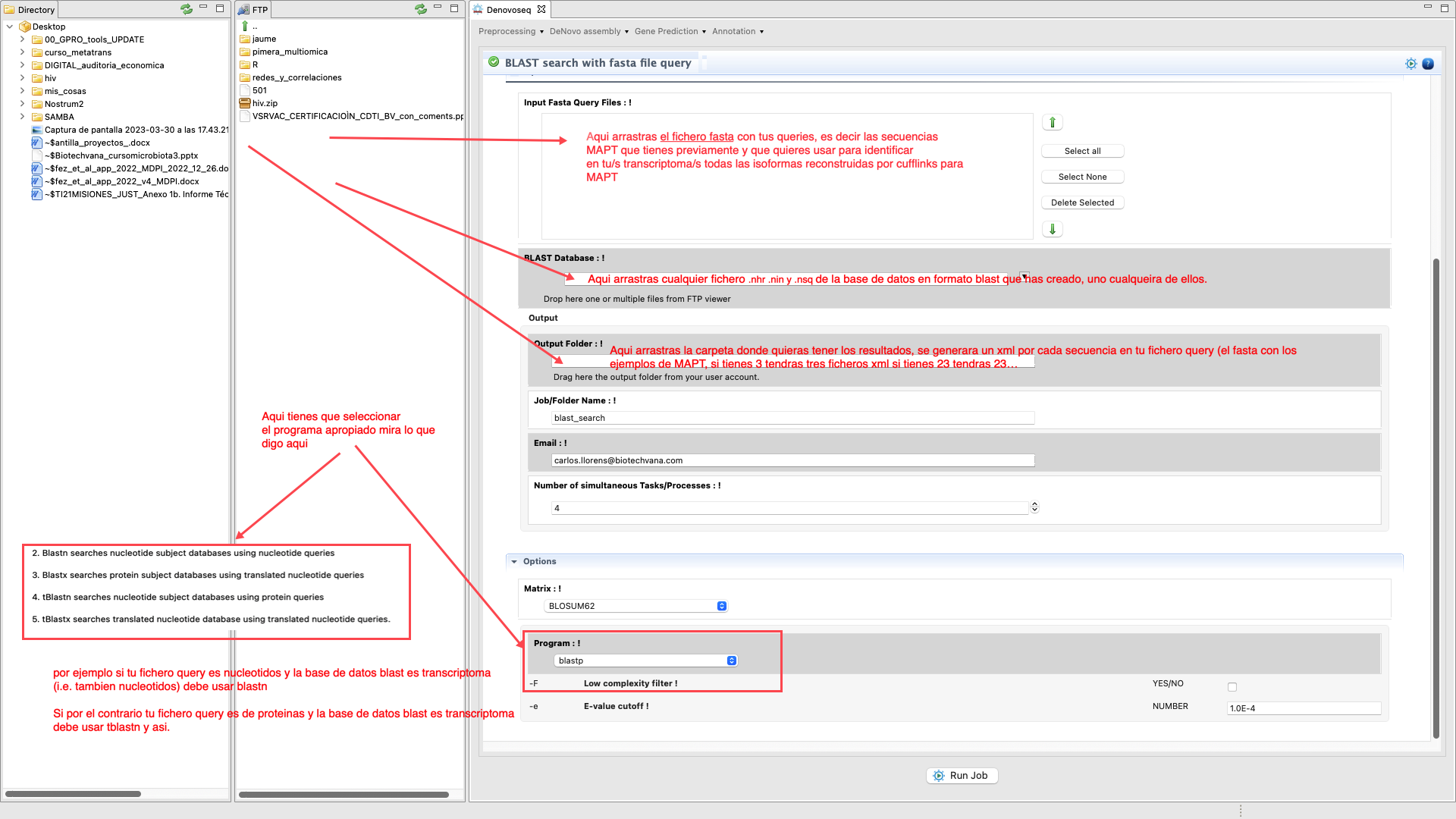
las pones en un fasta y mapeas sobre este fasta con Bowtie y luego cuantificas
con corset. Pero esto es bastante laborioso y tienes que ir con cuidado para
no cometer errores, y no le veo demasiadas ventajas sobre
usar cuffmerge para que sea el propio cufflinks quien te reconstruya
automaticamente las secuencias. Si sigues prefiriendo este segundo metodo , lo
facil aqui seria hacer un script para extraer automaticamente los exones
y crear todas esas isoformas. Si prefieres hacerlo asi de esta segunda manera
y quieres te preparamos esa base de datos de secuencias, dinoslo y lo hacemos
en un momento.
Dinos algo sobre esto.
Carlos